
Créer son CV devient un jeu d’enfant
DoYouBuzz est là pour vous simplifier la vie, c'est tout ! Nous respectons votre vie privée et ne vendons pas vos données personnelles à des tiers. Nous n'utilisons pas non plus de stratégie marketing pour vous retenir ou vous influencer.

Nos clients ont apprécié

Le gain de temps
Arnaud
Business Developper
Avec DoYouBuzz, j’ai été guidé et j’ai créé mon CV sans avoir à me soucier de la mise en page. Lors de mes entretiens, les recruteurs m’ont souvent demandé comment j’avais fait un CV pareil !

Nos conseils précieux
Suzanne
Assistante de gestion
Les conseils CV donnés lors des ateliers ont été très instructifs ! On a toujours des choses à modeler ou à changer sur son CV, et les directives données m'ont aidée à remettre les pendules à l'heure.

La bienveillance de l’équipe
Coralie
Chargée d’accueil
Je suis ravie de voir qu’une entreprise peut être super sympathique, j’adorerais travailler dans un environnement aussi fun et humain.
Merci pour l’exemple !
Un CV DoYouBuzz, comment ça marche ?

Je crée mon contenu

Je choisis et je personnalise mon modèle

Je demande de l'aide

Je fais relire mon CV

Je crée plusieurs versions de mon cv
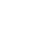
Je télécharge ou partage mon CV
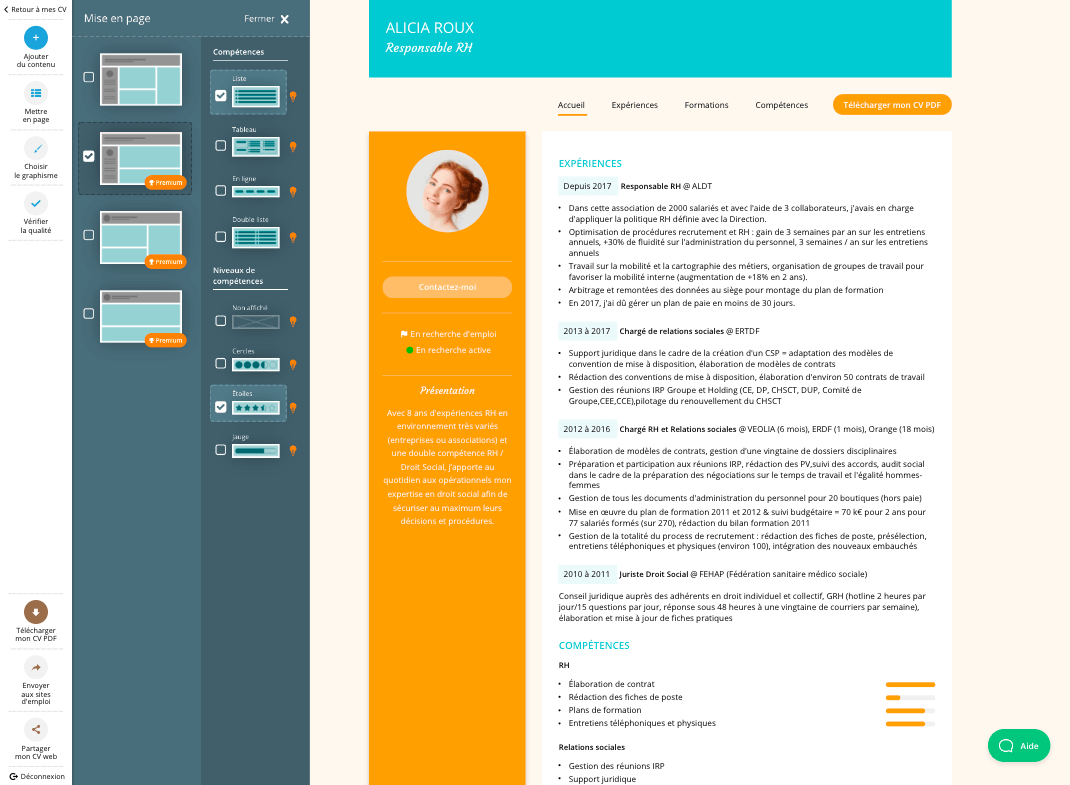

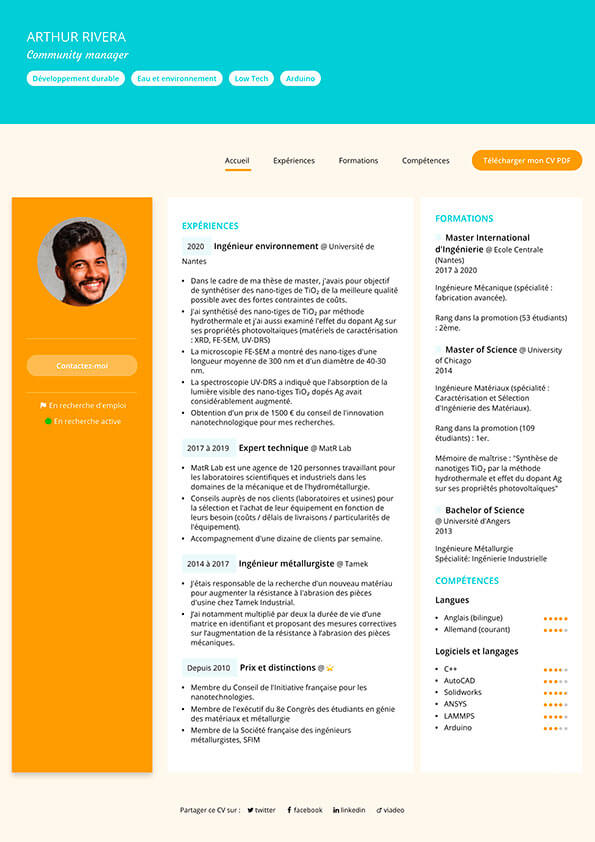





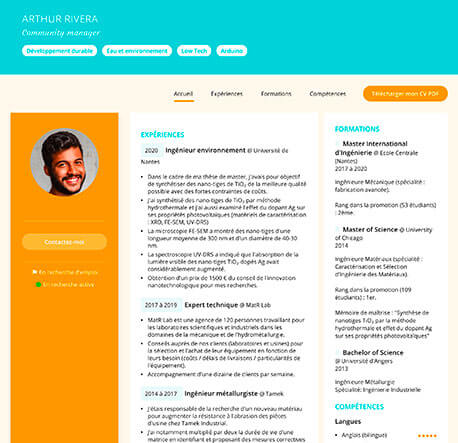
Comment choisir le bon modèle de CV
Modèle de CV pour les reconversions
Modèle de CV pour les seniors
Modèle de CV pour les étudiants sans expérience
Nos abonnements
Gratuit
Éditez un CV téléchargeable au format PDF

0 €
Premium Candidatures
Accédez à tous les designs et créez autant de CV que vous le désirez. Profitez de notre aide par email ou lors d'ateliers vidéos en direct

4,90 € / mois
Premium Visibilité
Diffusez votre CV sur le web avec un nom de domaine professionnel et consultez vos statistiques de visites

39,90 € / an
Notre solution pour les ESN
et les sociétés de conseils
Ce sont nos clients qui en parlent le mieux...
Bertrand Bailly - PDG de Davidson Consulting
Avant, pour bien présenter le parcours et les compétences d’un consultant, nous avions un modèle sous Word que chaque collaborateur devait respecter.
En pratique, les consultants passaient plusieurs heures à se débattre dans Word. Les CV conservaient des look & feel très hétérogènes et cela contraignait une assistante à temps plein à faire un travail aussi pénible qu’ingrat de contrôle et de mise et remise en forme des CV.
Aujourd'hui, avec Showcase, nous gagnons du temps dans la réalisation et la mise à jour des DC pour le consacrer au recrutement et à nos relations client.

FAQ DoYouBuzz
Qu’est-ce qu’un CV ?
Un CV, ou Curriculum Vitae, est un document écrit qui accompagne une candidature à un poste. Il a pour objectif de présenter de manière efficace les informations les plus importantes concernant le parcours professionnel et les compétences du candidat pour informer et convaincre le recruteur de l'adéquation de son profil avec le poste à pourvoir.
Le CV est généralement structuré en plusieurs rubriques, telles que les expériences professionnelles, la formation, les compétences et les centres d'intérêt. Il doit être clair, concis et facile à lire.
Le CV est un élément clé de la candidature, car il permet au recruteur de se faire une première idée des compétences et des expériences du candidat. C'est pourquoi il est important de prendre le temps de le rédiger de manière soignée et adaptée au poste visé !
Quelles informations mettre dans mon CV ?
- Vos informations personnelles : Nom, adresse, numéro de téléphone, adresse e-mail, photo (facultatif).
- Un titre de CV : Le nom du poste que vous visez, indispensable pour que le recruteur comprenne bien votre profil d’un coup d’oeil.
- Une phrase d'introduction : Une première étape de rédaction facultative qui explique brièvement qui vous êtes et ce que vous recherchez.
- Une section sur votre expérience professionnelle : Les postes que vous avez occupés, les compétences que vous avez acquises dans chaque job.
- Une section sur vos études et vos formations : Les diplômes que vous avez obtenus, les cours auxquels vous avez assisté
- Une rubrique sur vos compétences : Les compétences pertinentes pour le poste pour lequel vous postulez (hard skills / soft skills / logiciels maîtrisés). Ajoutez également vos Certifications si vous en avez pour montrer votre expertise.
- Une section sur vos centres d'intérêt : Cette rubrique facultative peut apporter un bonus à votre candidature. Elle nommera ce que vous aimez faire en dehors du travail et permettront de mettre en avant différentes qualités / compétences.
- Une section sur vos réalisations : Des informations sur des projets ou des réalisations auxquels vous avez contribué (facultatif).
Pour en savoir plus, parcourez nos différents articles sur le blog DoYouBuzz !
Comment faire un CV en PDF gratuit ?
Avec DoYouBuzz, vous pouvez télécharger gratuitement votre CV au format PDF. La version gratuite vous donne accès à un CV complet, à toutes nos recommandations et offre même la possibilité de disposer d'un CV Web accessible en un clic (doyoubuzz.com/prenom-nom).
En plus de la création de CV gratuits, nos différents abonnements Premium permettront :
- D'accéder à chaque design proposé par l’outil ;
- De créer plusieurs versions de CV ou encore ;
- D'obtenir votre CV en ligne avec un site web à votre nom.
Découvrez notre vidéo pour savoir comment faire un CV en PDF gratuit simplement avec DoYouBuzz !
Est-il possible de partager mon CV avec d’autres ?
Avec DoYouBuzz, il est possible de créer un CV gratuitement et de le télécharger au format PDF, mais aussi de disposer d'un lien web partageable en 1 clic à qui vous voudrez.
Cette fonction sera idéale pour partager votre CV à un proche pour une relecture et pour demander des suggestions d’amélioration ou une correction des fautes d’orthographe, mais aussi pour le partager directement à des recruteurs via un lien cliquable.
Exemple : www.doyoubuzz.com/freddie-mercury
Avec l'abonnement Premium Visibilité, vous pouvez, en plus d'autres avantages, disposer en quelques clics de votre curriculum vitae en ligne avec un site web à votre nom pour partager facilement vos informations et booster vos candidatures !
Exemple : www.freddie-mercury.fr
Puis-je enregistrer plusieurs versions de mon CV ?
Oui, une fois votre compte créé, vous pouvez effectuer plusieurs versions de votre curriculum vitae pour les adapter simplement aux offres qui vous intéressent dans votre recherche d'emploi !
- Avec la formule gratuite : Vous disposez d'un unique CV que vous pouvez modifier autant que vous voudrez.
- Avec les formules payantes : Vous pouvez enregistrer autant de versions de votre CV que vous souhaiterez.
Puis-je ajouter une photo à mon CV ?
DoYouBuzz permet d'ajouter une photo à votre curriculum vitae très simplement, et ce, avec chaque modèle, qu'ils soient gratuits ou inclus dans nos abonnements Premium.
Pour en savoir plus sur la photo sur le CV, nous avons préparé un article dédié qui vous expliquera tout ce qu'il faut faire ou ne pas faire à ce sujet !
Quels modèles de CV propose DoYouBuzz ?
DoYouBuzz propose un large choix de modèles gratuits et premium pour s'assurer que vous trouviez le modèle qui vous correspond ! Renseignez vos informations, choisissez votre design, modifiez les couleurs et c'est parti !
Plutôt sobre et moderne ? Vous préférez un CV original et coloré ? Parcourez tous nos modèles de CV pour trouver LE CV qui vous ressemble !
Pourquoi créer son CV en ligne avec DoYouBuzz ?
On le sait, rédiger son CV Canva ou avec un logiciel comme Word peut être un véritable parcours du combattant. Ici, vous profitez d'un outil conçu pour simplifier au maximum la rédaction de votre CV avec des blocs déjà placés, prêts à être remplis. Ce que Word et Canva ne proposent pas.
Nos recommandations avisées d'experts du CV depuis plus de 15 ans, régulièrement mis à jour, disponibles sur notre blog et accessibles tout au long de la rédaction de votre CV !
Pourquoi utiliser DoYouBuzz plutôt que Canva pour faire son CV en ligne gratuitement ?
À l'inverse de Canva, DoYouBuzz vous simplifie la rédaction de CV en vous accompagnant tout au long de sa rédaction et en mettant à disposition des "blocs" déjà bien placés pour obtenir un CV professionnel simplement.
Un bon CV se travaille plusieurs fois au cours de la recherche d’emploi. Si vous utilisez Canva, vous serez bloqué dans une seule mise en page, et chaque adaptation de votre CV vous demandera des efforts supplémentaires. Avec DoYouBuzz, la mise en page s’adapte en 2 clics !
DoYouBuzz, c'est plus de 15 ans d'expertise sur le sujet riche de la création de CV. Canva est un outil graphique ultra-performant sur le web qu'on apprécie pour ses multiples fonctions, mais il sera bien limité pour la rédaction d'un CV. Pour ne pas faire d'erreur, faites confiance à un spécialiste sur le sujet et laissez-vous guider facilement par l’outil !
Quel est l'impact du CV dans la recherche d'emploi ?
Le CV est un outil essentiel pour les demandeurs d’emploi, il est le premier contact entre un candidat et un recruteur avec (ou avant) la lettre de motivation. Il permettra de présenter son parcours (qualifications, compétences, expériences professionnelles, etc.).
Il sert de base pour déterminer si le profil d'un candidat est qualifié pour un poste lors du processus de recrutement
Il est donc crucial pour un demandeur d’emploi de bien rédiger son CV, mais aussi de le mettre à jour régulièrement et de l'adapter au poste convoité afin de maximiser ses chances de décrocher un emploi.
Que trouve-t-on sur le blog DoYouBuzz ?
Notre souhait ? Créer une encyclopédie du CV avec des recommandations de professionnels du CV, des informations sourcées et étudiées, mais aussi des retours de recruteurs sur le sujet.
Comment remplir la rubrique "Compétences" ? Comment bien rédiger une lettre de motivation ? Comment valoriser mes expériences ? Comment remplir la rubrique "Formations" ? Comment mettre en avant son profil pour postuler pour une offre d'emploi ? Quelles sont les étapes de création d'un CV ?
Parcourez notre blog pour être accompagné dans la création de votre CV !